Regular Expressions
Topics related to Regular Expressions:
Getting started with Regular Expressions
For many programmers the regex is some sort of magical sword that they throw to solve any kind of text parsing situation. But this tool is nothing magical, and even though it's great at what it does, it's not a full featured programming language (i.e. it is not Turing-complete).
What does 'regular expression' mean?
Regular expressions express a language defined by a regular grammar that can be solved by a nondeterministic finite automaton (NFA), where matching is represented by the states.
A regular grammar is the most simple grammar as expressed by the Chomsky Hierarchy.

Simply said, a regular language is visually expressed by what an NFA can express, and here's a very simple example of NFA:
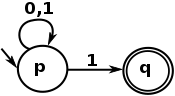
And the Regular Expression language is a textual representation of such an automaton. That last example is expressed by the following regex:
^[01]*1$
Which is matching any string beginning with 0 or 1, repeating 0 or more times, that ends with a 1. In other words, it's a regex to match odd numbers from their binary representation.
Are all regex actually a regular grammar?
Actually they are not. Many regex engines have improved and are using push-down automata, that can stack up, and pop down information as it is running. Those automata define what's called context-free grammars in Chomsky's Hierarchy. The most typical use of those in non-regular regex, is the use of a recursive pattern for parenthesis matching.
A recursive regex like the following (that matches parenthesis) is an example of such an implementation:
{((?>[^\(\)]+|(?R))*)}
(this example does not work with python's re engine, but with the regex engine, or with the PCRE engine).
Resources
For more information on the theory behind Regular Expressions, you can refer to the following courses made available by MIT:
- Automata, Computability, and Complexity
- Regular Expressions & Grammars
- Specifying Languages with Regular Expressions and Context-Free Grammars
When you're writing or debugging a complex regex, there are online tools that can help visualize regexes as automatons, like the debuggex site.
Matching Simple Patterns
Greedy and Lazy quantifiers
Greediness
A greedy quantifier always attempts to repeat the sub-pattern as many times as possible before exploring shorter matches by backtracking.
Generally, a greedy pattern will match the longest possible string.
By default, all quantifiers are greedy.
Laziness
A lazy (also called non-greedy or reluctant) quantifier always attempts to repeat the sub-pattern as few times as possible, before exploring longer matches by expansion.
Generally, a lazy pattern will match the shortest possible string.
To make quantifiers lazy, just append ? to the existing quantifier, e.g. +?, {0,5}?.
Concept of greediness and laziness only exists in backtracking engines
The notion of greedy/lazy quantifier only exists in backtracking regex engines. In non-backtracking regex engines or POSIX-compliant regex engines, quantifiers only specify the upper bound and lower bound of the repetition, without specifying how to find the match -- those engines will always match the left-most longest string regardless.
Anchor Characters: Caret (^)
Terminology
The Caret (^) character is also referred to by the following terms:
- hat
- control
- uparrow
- chevron
- circumflex accent
Usage
It has two uses in regular expressions:
- To denote the start of the line
- If used immediately after a square bracket (
[^) it acts to negate the set of allowed characters (i.e.[123]means the character 1, 2, or 3 is allowed, whilst the statement[^123]means any character other than 1, 2, or 3 is allowed.
Character Escaping
To express a caret without special meaning, it should be escaped by preceding it with a backslash; i.e. \^.
Lookahead and Lookbehind
Not supported by all regex engines.
Additionally, many regex engines limit the patterns inside lookbehinds to fixed-length strings. For example the pattern (?<=a+)b should match the b in aaab but throws an error in Python.
Capturing groups are allowed and work as expected, including backreferences. The lookahead/lookbehind itself is not a capturing group, however.
Capture Groups
Recursion
Recursion is mostly available in Perl-compatible flavors, such as:
- Perl
- PCRE
- Oniguruma
- Boost
Named capture groups
Python and Java don't allow multiple groups to use the same name.
Backtracking
Match Reset: \K
Regex101 defines \K functionality as:
\Kresets the starting point of the reported match. Any previously consumed characters are no longer included in the final match
The \K escape sequence is supported by several engines, languages or tools, such as:
- boost (since ???)
- grep -P ← uses PCRE
- Oniguruma (since 5.13.3)
- PCRE (since 7.2)
- Perl (since 5.10.0)
- PHP (since 5.2.4)
- Ruby (since 2.0.0)
...and (so far) not supported by:
UTF-8 matchers: Letters, Marks, Punctuation etc.
Word Boundary
Anchor Characters: Dollar ($)
A great deal of regex engines use a "multi-line" mode in order to search several lines in a file independently.
Therefore when using $, these engines will match all lines' endings. However, engines that do not use this kind of multi-line mode will only match the last position of the string provided for the search.
Character classes
Simple classes
| Regex | Matches |
|---|---|
[abc] | Any of the following characters: a, b, or c |
[a-z] | Any character from a to z, inclusive (this is called a range) |
[0-9] | Any digit from 0 to 9, inclusive |
Common classes
Some groups/ranges of characters are so often used, they have special abbreviations:
| Regex | Matches |
|---|---|
\w | Alphanumeric characters plus the underscore (also referred to as "word characters") |
\W | Non-word characters (same as [^\w]) |
\d | Digits (wider than [0-9] since include Persian digits, Indian ones etc.) |
\D | Non-digits (shorter than [^0-9] since reject Persian digits, Indian ones etc.) |
\s | Whitespace characters (spaces, tabs, etc...) Note: may vary depending on your engine/context |
\S | Non-whitespace characters |
Negating classes
A caret (^) after the opening square bracket works as a negation of the characters that follow it. This will match all characters that are not in the character class.
Negated character classes also match line break characters, therefore if these are not to be matched, the specific line break characters must be added to the class (\r and/or \n).
| Regex | Matches |
|---|---|
[^AB] | Any character other than A and B |
[^\d] | Any character, except digits |
Regular Expression Engine Types
Useful Regex Showcase
Back reference
Escaping
When you should NOT use Regular Expressions
Because regular expressions are limited to either a regular grammar or a context-free grammar, there are many common misuses of regular expressions. So in this topic there are a few example of when you should NOT use regular expressions, but use your favorite language instead.
Some people, when confronted with a problem, think:
“I know, I'll use regular expressions.”
Now they have two problems.
— Jamie Zawinski
Regex modifiers (flags)
PCRE Modifiers
| Modifier | Inline | Description |
|---|---|---|
| PCRE_CASELESS | (?i) | Case insensitive match |
| PCRE_MULTILINE | (?m) | Multiple line matching |
| PCRE_DOTALL | (?s) | . matches new lines |
| PCRE_ANCHORED | (?A) | Meta-character ^ matches only at the start |
| PCRE_EXTENDED | (?x) | White-spaces are ignored |
| PCRE_DOLLAR_ENDONLY | n/a | Meta-character $ matches only at the end |
| PCRE_EXTRA | (?X) | Strict escape parsing |
| PCRE_UTF8 | Handles UTF-8 characters | |
| PCRE_UTF16 | Handles UTF-16 characters | |
| PCRE_UTF32 | Handles UTF-32 characters | |
| PCRE_UNGREEDY | (?U) | Sets the engine to lazy matching |
| PCRE_NO_AUTO_CAPTURE | (?:) | Disables auto-capturing groups |
Java Modifiers
Modifier (Pattern.###) | Value | Description |
|---|---|---|
| UNIX_LINES | 1 | Enables Unix lines mode. |
| CASE_INSENSITIVE | 2 | Enables case-insensitive matching. |
| COMMENTS | 4 | Permits whitespace and comments in a pattern. |
| MULTILINE | 8 | Enables multiline mode. |
| LITERAL | 16 | Enables literal parsing of the pattern. |
| DOTALL | 32 | Enables dotall mode. |
| UNICODE_CASE | 64 | Enables Unicode-aware case folding. |
| CANON_EQ | 128 | Enables canonical equivalence. |
| UNICODE_CHARACTER_CLASS | 256 | Enables the Unicode version of Predefined character classes and POSIX character classes. |
Password validation regex
Possessive Quantifiers
Atomic Grouping
A possessive quantifier behaves like an atomic group in that the engine will be unable to backtrack over a token or group.
The following are equivalent in terms of functionality, although some will be faster than others:
a*+abc
(?>a*)abc
(?:a+)*+abc
(?:a)*+abc
(?:a*)*+abc
(?:a*)++abc